400-665-9980 | 15920999917(客户专线)

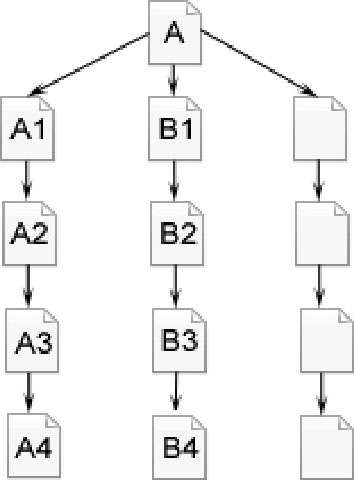
如图2-25所示,蜘蛛跟踪链接,从A页面爬行到A1、A2、A3、A4,到A4页面后,已经没有其他链接可以跟踪就返回A页面,顺着页面上的另一个链接,爬行到B1、B2、B3、B4。在深度优先策略中,蜘蛛一直爬到无法再向前,才返回爬另一条线。
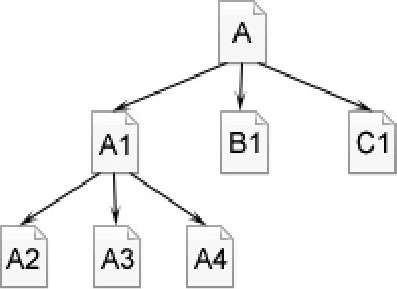
如图2-26所示,蜘蛛从A页面顺着链接爬行到A1、B1、C1页面,直到A页面上的所有链接都爬行完,然后再从A1页面发现的下一层链接,爬行到A2、A3、A4、……页面。
大部分主流搜索引擎都提供一个表格,让站长提交网址。不过这些提交来的网址都只是存入地址库而已,是否收录还要看页面重要性如何。搜索引擎所收录的绝大部分页面是蜘蛛自己跟踪链接得到的。可以说提交页面作用微乎其微,搜索引擎更喜欢自己沿着链接发现新页面。

全国售后支持123
14年行业服务经验
全国售后支持
超百人设计、研发团队
服务企业客户2万家
连续9年守合同重信用企业
 建站咨询
SEO优化咨询
小程序咨询
建站咨询
SEO优化咨询
小程序咨询
地 址:广州市黄埔区锐丰中心1号楼922-929
业务热线:020-32379980 售后专线:020-28999180
业务一部QQ:840908885  业务二部QQ:840908885
业务二部QQ:840908885
地 址:深圳市龙华新区布龙路荣应大厦1105
业务热线:15920999917 售后专线:15920999917
业务一部QQ:840908885
业务二部QQ:840908885
地 址:长沙市雨花区德思勤城市广场A8栋3024
业务热线:0731-88612341 售后专线:13723888441
业务一部QQ:840908885
业务二部QQ:493102355
对公帐户:广州联享信息科技有限公司
开户银行:中国工商银行广州石牌支行 账号:3602 0986 0920 0130 274
| 银行 | 户名 | 开户行 | 帐号 |
|---|---|---|---|
| 支付宝 | 广州联享信息科技有限公司 | 支付宝 | 123@a020.net |
| 中国工商银行 | 杨雄 | 广州车陂支行 | 6212 2636 0202 8813 145 |
| 中国银行 | 杨雄 | 长沙市贺龙支行 | 6217 8575 0002 4885 045 |
| 中国农业银行 | 杨雄 | 长沙天心区支行 | 6228 4810 9946 1564 479 |
